
辅助驾驶好不好用,还是要看实际表现,3月11日小鹏全国732家门店试驾开启!
小鹏第二代VLA来了,不是期货,不是画饼,月底推送!大众是首发客户,还有其它车企正在洽谈中!
搭载第二代VLA的Robotaxi测试车小鹏GX,已经在主驾无人、园区无图的情况下完成了:原地起步、自主行驶、靠边停车、接客起步、计费等全部的操作流程,今年会在广州给大家开放试驾。

5000公里智驾横穿中国也即将启动。
2026年,还会实现VLA+VLM驾舱一体、Max版本推送蒸馏版第二代VLA、Robotaxi开启运营。
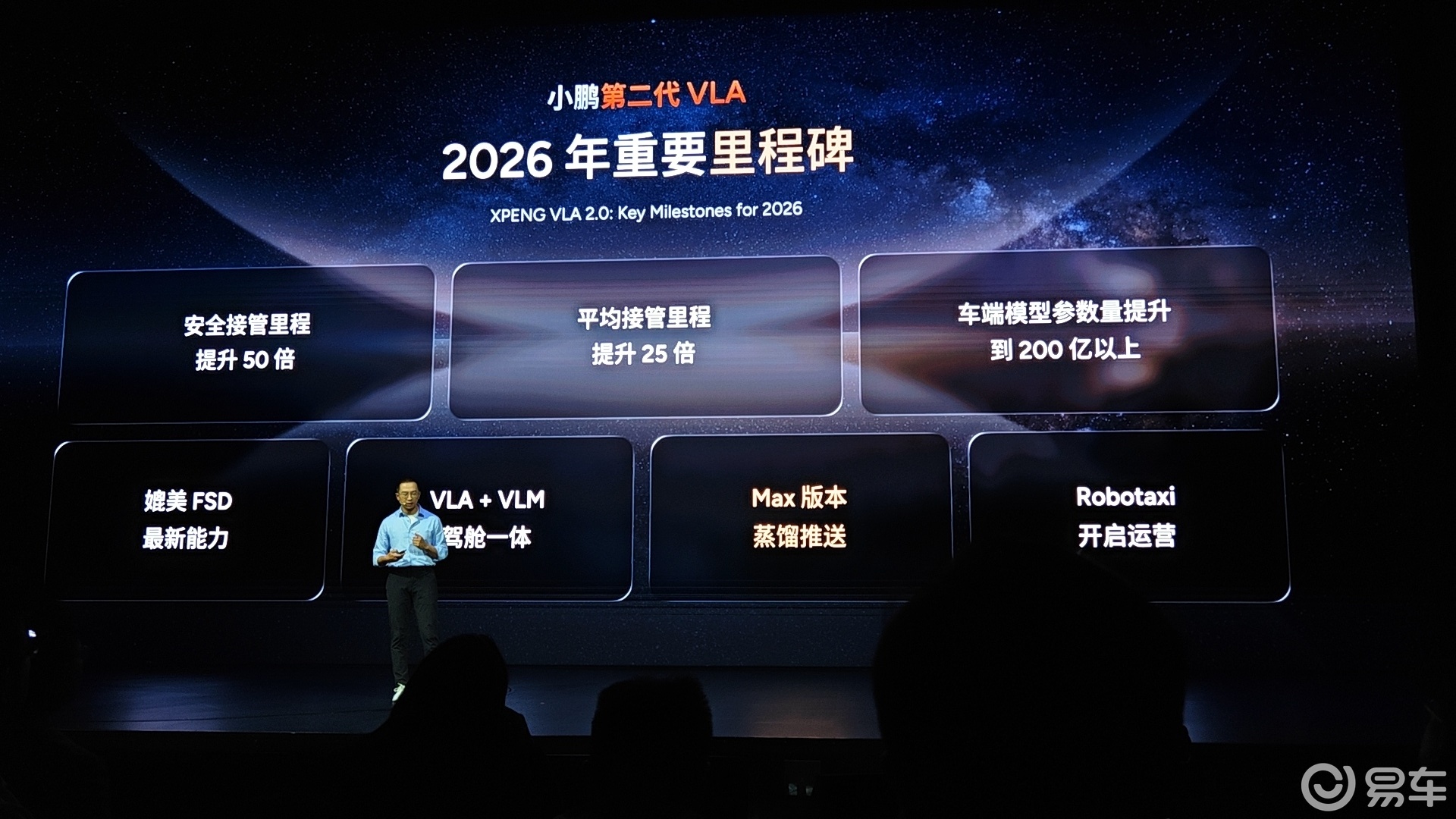
全球路测即将开始,2027年开启全球交付。


第二代VLA上用到的技术咱们后面再讲,先看看实测吧,白天、黑天、雨天、小路、烂路、开门杀场景全都有,老司机看了都得直呼专业!
开门杀绕行:这个确实6!

不过我早就知道VLA可以应对类似场景,在第一代VLA上我就体验过了,路边静止车辆毫无征兆起步并一把拐进来,VLA直接从8km/h速度下的加速状态丝滑刹停,车内乘员完全不知道发生了什么,只有我内心感叹:可能我也不一定比它刹得平稳!
绕行事故车辆:这个确实6的飞起啊!请收下我的膝盖。

起伏烂路提前减速:

乡村小路避坑:

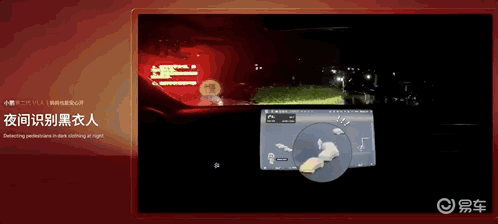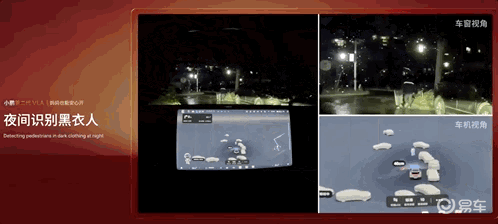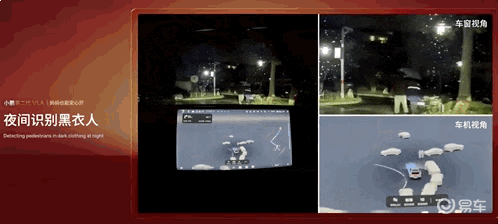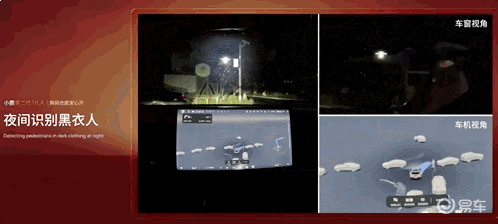
夜间识别黑衣路人:
夜间让行小动物:

夜间绕行桩桶:

窄路通行:

暴雨天气:

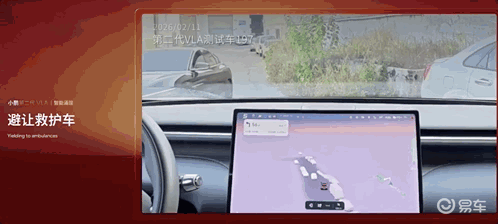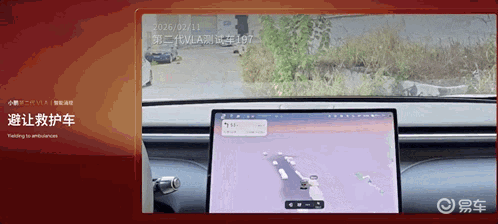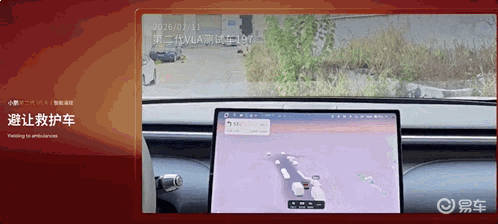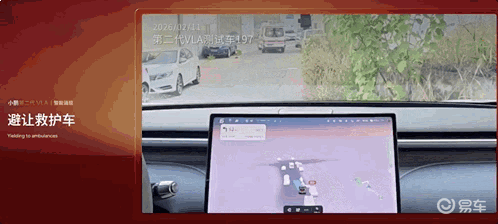
避让救护车:
查酒驾主动停车:

停车场漫游和城市漫游:

这些场景都能处理好已经很不错了,更加厉害的是通行效率还非常高,甚至用时比导航给出的还要短!

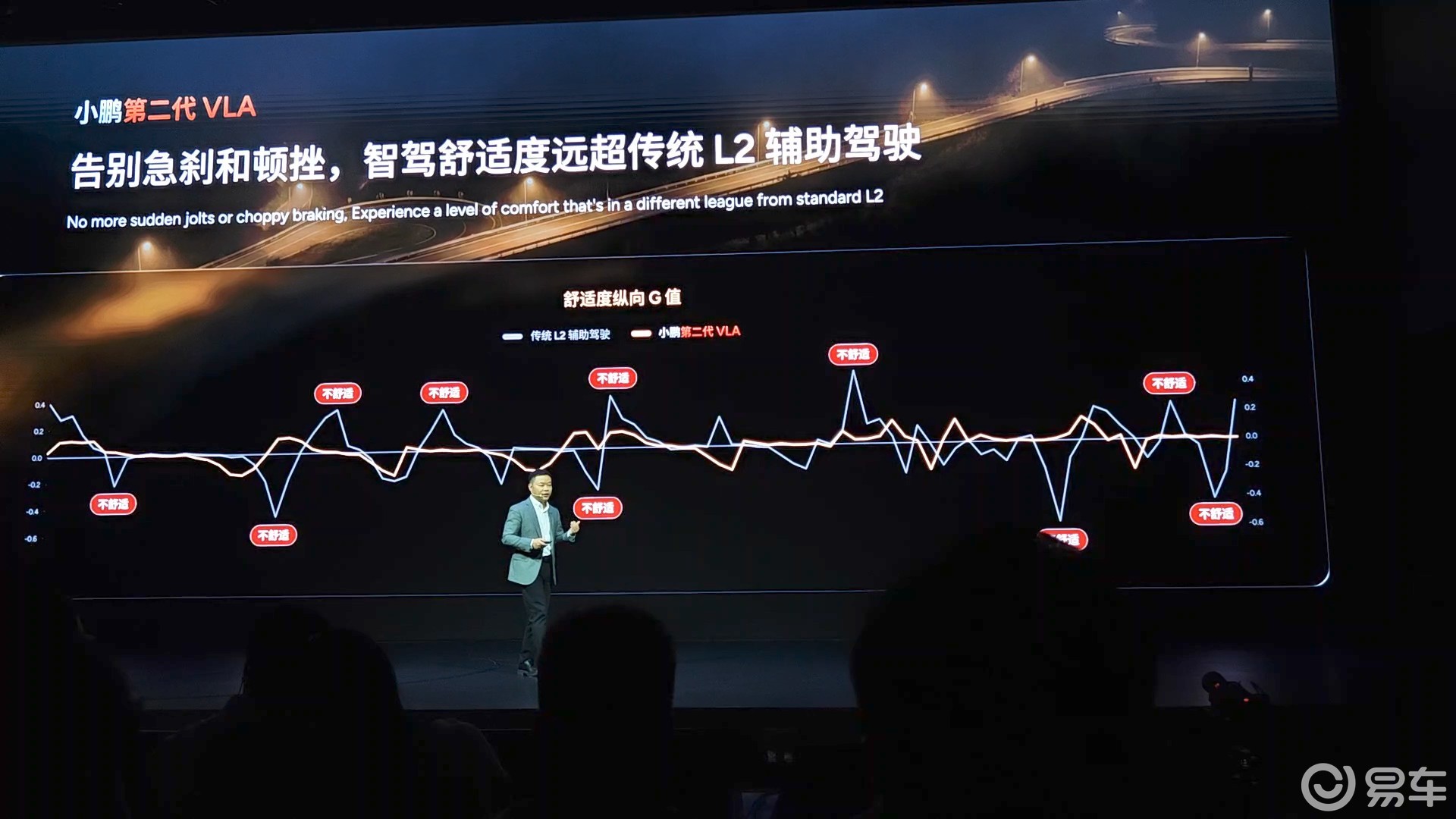
而且智驾舒适度远超传统L2级辅助驾驶。
还是全场景都能开,而且今年还会实现所有道路的体验都能像城市主路一样能做到99分那么好!

第二代VLA技术讲解
自动驾驶本质上是物理AI的问题,涉及到模型、算力、数据、本体。

物理世界比数字世界复杂度是指数级上升的,物理世界的输入信号是连续的、非结构化的,信息量大,而且不像文字一样可以去做分词和拆解。

为了处理连续信号和多模态的输入信号,小鹏设计了一套原生多模的信号处理单元,它能更高效、更原始的编码所有的信号,并且进入特别早期的融合,来避免单一模态带来的偏差。




物理世界比较复杂,需要一套特别长、特别快速的推理逻辑,这就需要视觉推理的思维链的技术,为了能够跑到实时,小鹏把视觉思维链的效率提升了32倍。而最后的输出是多模态的,能生成视频、声音、动作、行为,不仅仅是支撑第二代VLA的底层的基本底座,也是支撑小鹏去做世界模型、仿真、强化学习的基础框架。
这个多模态的模型,也是小鹏继续去做下一步,原生的舱驾一体、舱驾联动的基本框架。


小鹏自研了图灵芯片,根据目标场景和应用情况设计专门的底层硬件架构,同时也在上面打造了一套AI的编译器,让模型在上面跑得更加丝滑和高效,还根据芯片和编译器重新定义和设计了底座模型的基本结构。 因此,模型在车端运行的效率提升了12倍,可以让模型跑到一个实时的帧率,摄像头多快模型就多快。

访存和计算是AI模型两个基本的操作,在说AI芯片效率的时候,计算的占用密度越高,就说明芯片的利用效率越高。经过芯片、模型结构 的深度定制,编译器的联合优化,小鹏把硬件的利用效率从22.5%(通用芯片+开源模型),提升到82.5%(图灵芯片+图灵模型)。


有效算力是名义算力乘以芯片算力利用率,一颗图灵芯片名义算力大概是Orin X的三倍,经过了全场景的重构和优化之后,现在一颗图灵芯片的有效算力接近十颗Orin X的有效算力。

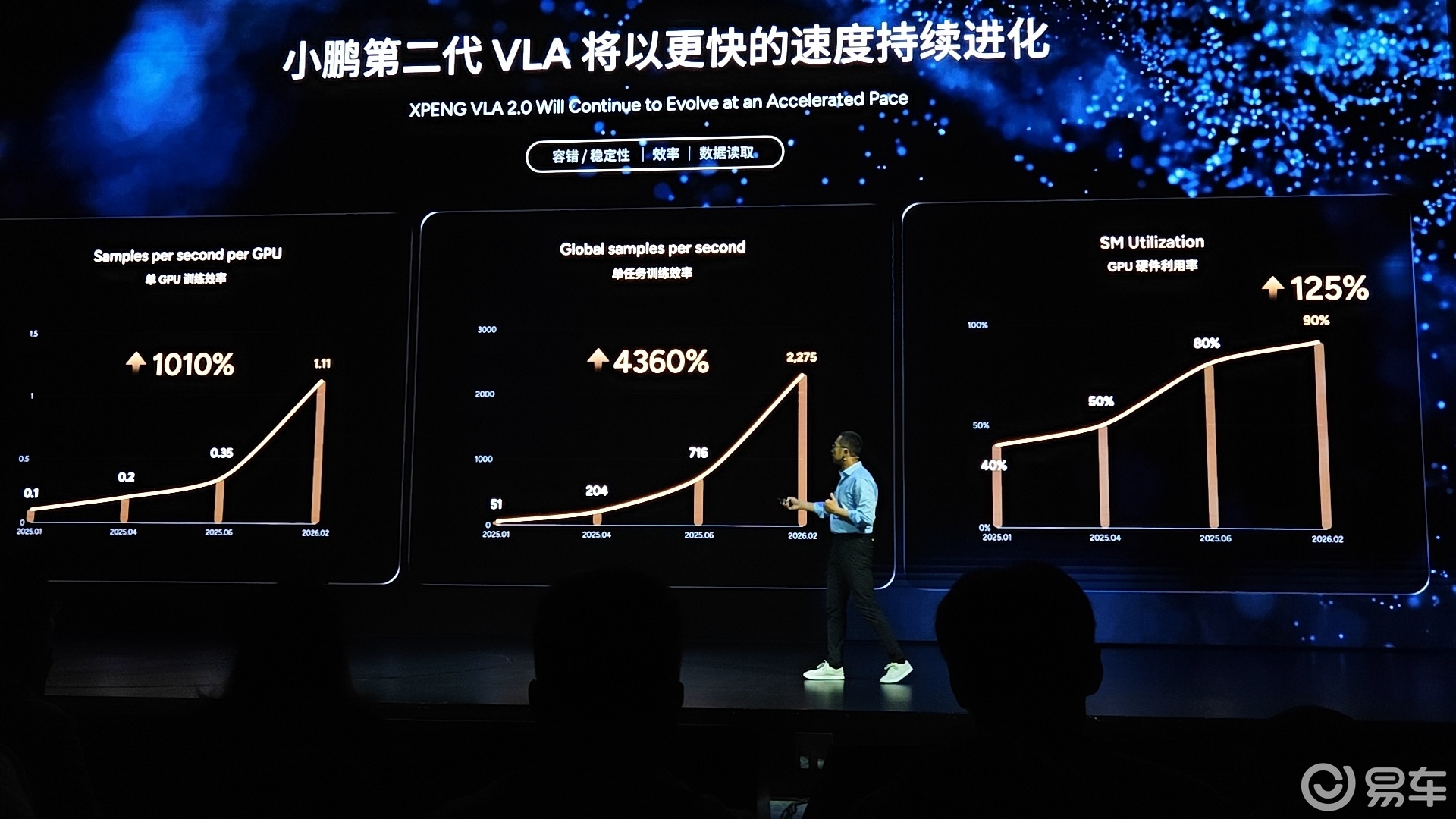
小鹏VLA会以更快的速度进化,从2025年初到2026年初,单颗GPU的训练效率提升1010%、单个任务的训练效率提升4360%、GPU硬件利用率提升125%,不停的在优化模型和训练过程中的容错性、稳定性、训练的效率(硬件利用率)和数据读取的有效效率。
训练过程当中,高质量的Token越多,模型的性能一般就会越强,泛化能力就会越强。现在在单次训练过程当中,云端的高质量数据达到了50PB左右的规模,这已经是正常训练一个基于语言的大模型的20倍左右的数据量。
同时因为输入的是高密度的摄像头和传感器数据,现在车上7颗摄像头,带来的高帧率、高分辨率的数据达到每秒53亿字节,是其它传感器正常的20~50倍左右。现在训练每版模型的整体的Token数量达到4万亿左右。这也是训练ChatGPT左右规模的训练数据的规模。

这说明物理世界确实比数字世界更加复杂,它的数据密度,对于算力的消耗,都要远远超过数字世界的,必须要有强大的算力和数据处理能力作为基础,才可能真正做好物理AI,去做好高阶自动驾驶。
仿真测试:小鹏的仿真场景从一年前的3万个,增加到50多万个,一天的仿真测试当量相当于人去跑3000万公里的测试数据。同时把世界模型应用于仿真测试里,同一个鬼探头场景,让世界模型生成不同的程度,并且让模型去测试。不同于传统的基于重建再去生成的方式的仿真,基于世界模型的方式可以更自然、更交互的去生成真实的使用场景,在不同的场景里面给它不同的条件,是会给你不同的结果的。正是有了这样极限的仿真测试的情况,才能保证大家拿到手的软件是一个足够安全,并且能够足够泛化的,否则是没有办法采集到 那么多跟安全相关的训练和测试数据的。

把世界模型用于强化学习,做自我博弈 ,让世界模型根据第二代VLA输出的轨迹去重新生成它对这个世界的理解,两个过程是交互的,VLA输出一个动作,世界模型生成一个新的场景,再拿过来去做新的基础数据,再去输出下一帧,整个是一个交互,是一个活的过程。正是如此,才能做自我博弈,让模型在虚拟世界里,在世界模型里变得越来越强大。
而生成一个几秒钟的视频是解决不了问题的,因为很多物理世界的问题是需要非常长时间的推演、推理的,这就需要长时序推演。


怎么样听懂了吗?嗨,甭管听没听懂,3月下旬就开启推送了,3月11日全国732家门店就可以体验到了,是骡子是马,拉出来溜溜!






